
申请日2018.02.11
公开(公告)日2018.09.04
IPC分类号G06N3/02
摘要
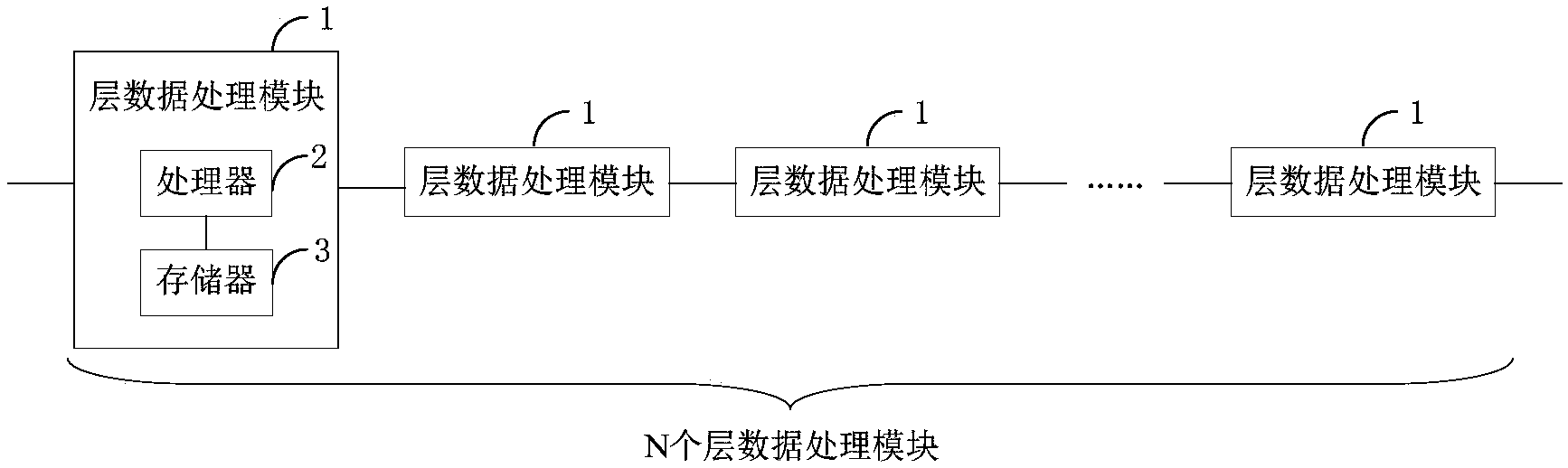
本发明涉及一种面向人工智能计算的神经网络数据串行流水处理装置及系统,装置包括:N个层数据处理模块;N个层数据处理模块串行连接;层数据处理模块包括:处理器及存储器;处理器,用于对神经网络的层数据进行并行运算及串行传输;存储器,用于存储并行运算涉及的所有数据;若多次向神经网络输入初始数据,则N个层数据处理模块对多次输入的初始数据进行流水处理。本发明通过每个层数据处理模块对本身所对应层的层数据进行并行运算,运算过程涉及的所有数据均在本层数据处理模块中存储,减少了运算过程中不断从外部存储读写数据和参数产生大量功耗和延迟的问题,同时对多次输入数据,可进行流水处理,提高神经网络数据的处理效率。
权利要求书
1.一种面向人工智能计算的神经网络数据串行流水处理装置,其特征在于,包括:N个层数据处理模块;
所述N个层数据处理模块串行连接;
所述层数据处理模块包括:数据输入端口、数据输出端口、处理器以及存储器;
所述数据输入端口连接上一层数据处理模块的数据输出端口;
所述数据输出端口连接下一层数据处理模块的数据输入端口;
所述处理器,用于对神经网络的层数据进行并行运算以及串行传输;所述存储器,用于存储所述并行运算涉及的所有数据;
若多次向所述神经网络输入初始数据,则所述N个层数据处理模块,用于对多次输入的初始数据进行流水处理。
2.根据权利要求1所述的装置,其特征在于,所述处理器,具体用于通过所述数据输入端口接收上一层数据处理模块的运算结果或所述神经网络的初始数据,并在接收到所述运算结果或所述初始数据后,对本身所对应层的层数据进行并行运算,且将所述并行运算涉及的所有数据均存储到所述存储器中,并将所述并行运算的运算结果通过所述数据输出端口串行输出。
3.根据权利要求2所述的装置,其特征在于,所述处理器,还用于在接收到所述运算结果或所述初始数据后,判断接收到的数据是否满足并行运算的预设最低条件;若满足,则执行所述对本身所对应层的层数据进行并行运算的步骤。
4.根据权利要求1所述的装置,其特征在于,所述处理器为多核处理器;
所述多核处理器,用于对神经网络的层数据进行核间并行运算以及串行传输。
5.根据权利要求1至4任一项所述的装置,其特征在于,所述层数据处理模块还包括:配置端口;
所述处理器连接所述配置端口;
所述处理器,还用于通过所述配置端口接收层数据配置信息。
6.一种面向人工智能计算的神经网络数据串行流水处理系统,其特征在于,包括:
主机、总线以及如权利要求5所述的神经网络数据串行流水处理装置;
所述主机通过所述总线分别连接所述N个层数据处理模块的配置端口;
所述主机,用于通过所述总线分别向所述N个层数据处理模块的配置端口发送对应的层数据配置信息。
说明书
一种面向人工智能计算的神经网络数据串行流水处理装置
技术领域
本发明实施例涉及计算机技术领域,具体涉及一种面向人工智能计算的神经网络数据串行流水处理装置及系统。
背景技术
神经网络是人工智能领域中应用最多的一种工具,神经网络的种类有多种,以深度卷积神经网络为例,深度卷积神经网络不同的模型具有不同层数,但主要计算类型有六种方式:全连接、卷积、池化、非线性、向量运算和矩阵加,这六种方式属于成熟技术,本文不再赘述。
神经网络模型的计算方式本质都是小矩阵的乘加运算,巨大的并行度带来巨大数据量,不断从外部存储读写数据和参数是其最大的瓶颈,将产生大量功耗和延迟。
上述对问题的发现过程的描述,仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
发明内容
为了解决现有技术存在的问题,本发明的至少一个实施例提供了一种面向人工智能计算的神经网络数据串行流水处理装置及系统。
第一方面,本发明实施例公开一种面向人工智能计算的神经网络数据串行流水处理装置,包括:N个层数据处理模块;
所述N个层数据处理模块串行连接;
所述层数据处理模块包括:数据输入端口、数据输出端口、处理器以及存储器;
所述数据输入端口连接上一层数据处理模块的数据输出端口;
所述数据输出端口连接下一层数据处理模块的数据输入端口;
所述处理器,用于对神经网络的层数据进行并行运算以及串行传输;所述存储器,用于存储所述并行运算涉及的所有数据。
若多次向所述神经网络输入初始数据,则所述N个层数据处理模块,用于对多次输入的初始数据进行流水处理。
可选的,所述处理器,具体用于通过所述数据输入端口接收上一层数据处理模块的运算结果或所述神经网络的初始数据,并在接收到所述运算结果或所述初始数据后,对本身所对应的层数据进行并行运算,且将所述并行运算涉及的所有数据均存储到所述存储器中,并将所述并行运算的运算结果通过所述数据输出端口串行输出。
可选的,所述处理器,还用于在接收到所述运算结果或所述初始数据后,判断接收到的数据是否满足并行运算的预设最低条件;若满足,则执行所述对本身所属层的层数据进行并行运算的步骤。
可选的,所述处理器为多核处理器;
所述多核处理器,用于对神经网络的层数据进行核间并行运算以及串行传输。
可选的,所述层数据处理模块还包括:配置端口;
所述处理器连接所述配置端口;
所述处理器,还用于通过所述配置端口接收层数据配置信息。
第二方面,本发明实施例公开一种面向人工智能计算的神经网络数据串行流水处理系统,包括:
主机、总线以及如第一方面所述的神经网络数据串行流水处理装置;
所述主机通过所述总线分别连接所述N个层数据处理模块的配置端口;
所述主机,用于通过所述总线分别向所述N个层数据处理模块的配置端口发送对应的层数据配置信息。
可见,本发明实施例的至少一个实施例中,通过将神经网络每层与层数据处理模块相对应,每个层数据处理模块对本身所对应层的层数据进行并行运算,运算过程涉及的所有数据均在本层数据处理模块中存储,减少了运算过程中不断从外部存储读写数据和参数产生大量功耗和延迟的问题,同时对多次输入数据,可进行流水处理,从而提高了神经网络数据的处理效率。