
°°°°…к«л»’2019.07.16
°°°°єЂњ™(єЂЄж)»’2019.09.17
°°°°IPCЈ÷јаЇ≈G06Q10/06; G06Q50/26; G06K9/62
°°°°’™“™
°°°°±ЊЈҐ√ч…жЉ∞їъ∆ч—Іѕ∞Ѕм”т£ђћЎ±р…жЉ∞“ї÷÷їщ”Џїъ∆ч—Іѕ∞µƒќџЋЃі¶јнµƒЋЃ÷ ‘§≤вЈљЈ®Љ∞ѕµЌ≥£ђЋщ цЈљЈ®∞ьј®»Јґ®ќџЋЃµƒ≤вЅњ≤ќ эЇЌќџЋЃі¶јнµƒ––“µ±к„Љ£ђ≤Ґ≥х ЉїѓќџЋЃµƒ≤вЅњ≤ќ э£ђ≤ҐљЂ≤вЅњ≤ќ эµƒћЎ’ч»®÷ЎѕтЅњ≥х Љїѓќ™1;їс»°ќџЋЃ≤вЅњ≤ќ эµƒ ”¶ґ»£ђљЂ ”¶ґ»„оіуµƒЄцће„чќ™„о”≈µƒЄцће;љЂ„о”≈µƒЄцћеЄі÷∆n‑1Єц£ђ≤Ґ‘Џ√њЄцЄі÷∆µƒЄцће…ѕµƒћЎ’ч»®÷Ў…ѕЉ”“їЄцЋжїъ÷µ;їс»°µ±«∞Єцћеµƒ ”¶ґ»£ђ—°‘с ”¶ґ»„оіуµƒЄцће„чќ™„о”≈µƒЄцће;»фіпµљ„оіуµьіъіќ э£ђ‘т д≥ц„о”≈µƒћЎ’ч»®÷ЎѕтЅњ;љЂµ√µљ„о”≈ћЎ’чѕтЅњ д»лѕя–‘÷І≥÷ѕтЅњїъ;љЂ µ ±ќџЋЃ≤вЅњ≤ќ э д»лЌк≥…—µЅЈµƒѕя–‘÷І≥÷ѕтЅњїъЉіњ…µ√µљ‘§≤вљбєы;±ЊЈҐ√чњ…“‘”––ІµЎґ‘ќџЋЃ÷ Ѕњљш––‘§≤в£ђќ™ µЉ µƒќџЋЃі¶јнћбє©Є®÷ъ°£
°°°°»®јы“™«у й
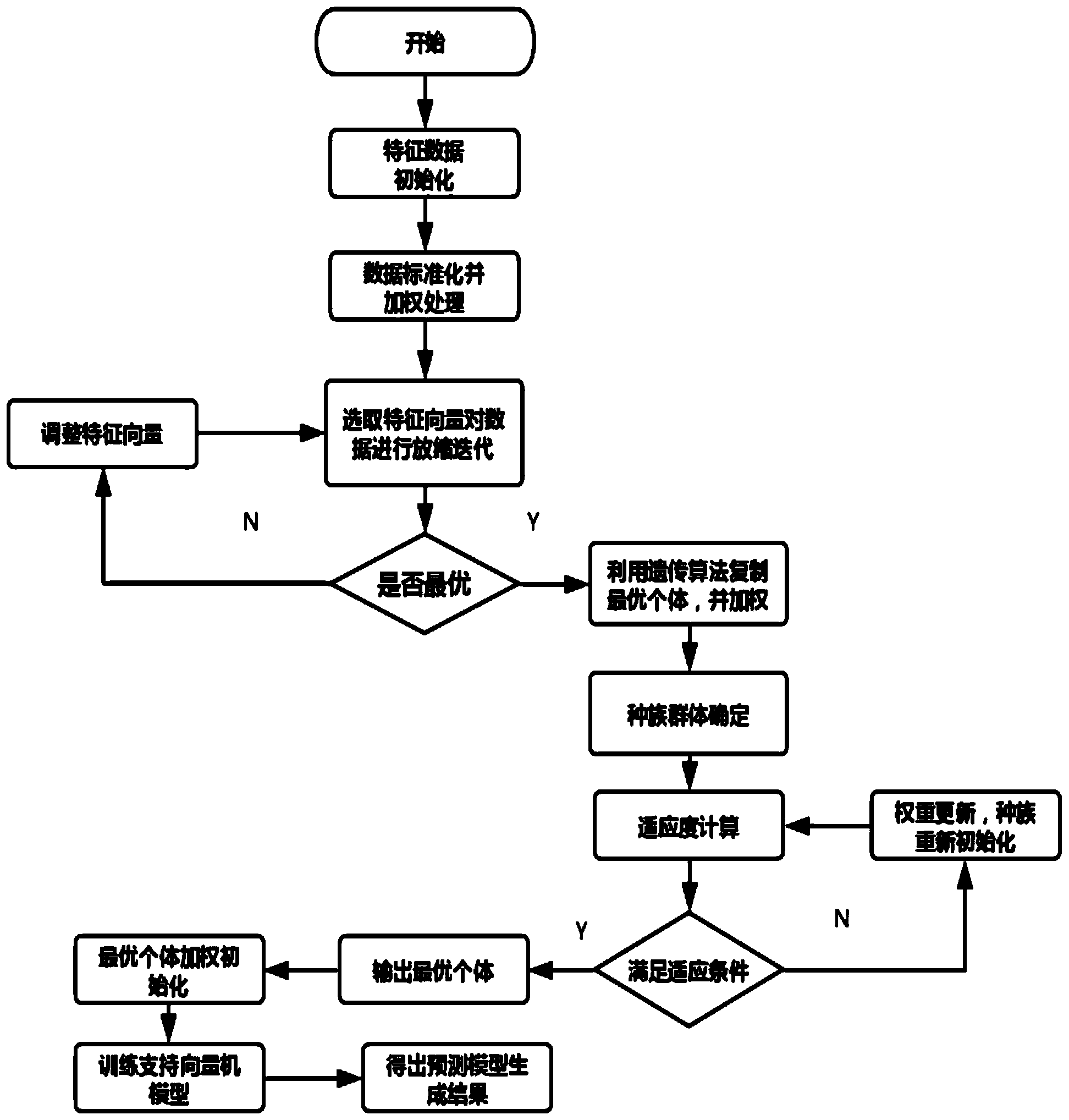
°°°°1.“ї÷÷їщ”Џїъ∆ч—Іѕ∞µƒќџЋЃі¶јнµƒЋЃ÷ ‘§≤вЈљЈ®£ђ∆дћЎ’ч‘Џ”Џ£ђЊяће∞ьј®“‘ѕ¬≤љ÷и£Ї
°°°°S1°Ґ»Јґ®ќџЋЃµƒ≤вЅњ≤ќ эЇЌќџЋЃі¶јнµƒ––“µ±к„Љ£ђ≤Ґ≥х ЉїѓќџЋЃµƒ≤вЅњ≤ќ э£ђ≤ҐљЂ≤вЅњ≤ќ эµƒћЎ’ч»®÷ЎѕтЅњ≥х Љїѓќ™1£ђ±н Њќ™ќ™v0(i)=1;Ћщ цќџЋЃµƒ≤вЅњ≤ќ э÷Ѕ…ў∞ьј®CODcr≥цЋЃ°ҐPH÷µ°Ґ»№љв—хDO°Ґ∞±µ™NH3-N;
°°°°S2°ҐЌ®єэѕя–‘÷І≥÷ѕтЅњїъїс»°ќџЋЃ≤вЅњ≤ќ эµƒ ”¶ґ»£ђљЂ ”¶ґ»„оіуµƒЄцће„чќ™„о”≈µƒЄцће£ђЅоi=1;
°°°°S3°Ґ‘ЏµЏiіќµьіъ÷–£ђљЂ„о”≈µƒЄцћеЄі÷∆n-1Єц£ђ≤Ґ‘Џ√њЄцЄі÷∆µƒЄцће…ѕµƒћЎ’ч»®÷Ў…ѕЋжїъЉ”…ѕ“їЄц«шЉд[0,max_variation]ƒЏµƒ÷µ;
°°°°S4°ҐЌ®єэѕя–‘÷І≥÷ѕтЅњїъїс»°µ±«∞Єцћеµƒ ”¶ґ»£ђ—°‘с ”¶ґ»„оіуµƒЄцће„чќ™„о”≈µƒЄцће;
°°°°S5°Ґ≈–ґѕ «Јсіпµљ„оіуµьіъіќ э£ђ»ф√їіпµљ‘тЅоi=i+1£ђЈµїЎ≤љ÷иS3;Јс‘т д≥ц„о”≈µƒћЎ’ч»®÷ЎѕтЅњ;
°°°°S6°ҐљЂµ√µљ„о”≈ћЎ’чѕтЅњ д»лѕя–‘÷І≥÷ѕтЅњїъљш––—µЅЈ£ђ—µЅЈЌк≥…ЇуљЂ µ ±ќџЋЃ≤вЅњ≤ќ э д»лѕя–‘÷І≥÷ѕтЅњїъ÷–£ђЉіњ…µ√µљ‘§≤вљбєы;
°°°°∆д÷–£ђnќ™‘§ґ®µƒ÷÷»Ї эЅњ;max_variationќ™‘§…иµƒµ•іъ„оіу±д“мґ»;vj(i)ќ™µЏjЄцќџЋЃµƒ≤вЅњ≤ќ эµƒћЎ’чѕтЅњ£ђ1°№i°№m£ђmќ™Є√≤вЅњ≤ќ эµƒћЎ’чѕтЅњµƒќђ э°£
°°°°2.ЄщЊЁ»®јы“™«у1Ћщ цµƒ“ї÷÷їщ”Џїъ∆ч—Іѕ∞µƒќџЋЃі¶јнµƒЋЃ÷ ‘§≤вЈљЈ®£ђ∆дћЎ’ч‘Џ”Џ£ђЋщ ц ”¶ґ»ќ™ЄцћеµƒF1Ј÷ э£ђF1Ј÷ эќ™÷І≥÷ѕтЅњїъ‘Џ—й÷§Љѓ…ѕµƒ–‘ƒ№≤ќ э°£
°°°°3.“ї÷÷їщ”Џїъ∆ч—Іѕ∞µƒќџЋЃі¶јнµƒЋЃ÷ ‘§≤вѕµЌ≥£ђ∆дћЎ’ч‘Џ”Џ£ђ∞ьј® эЊЁ д»лƒ£њй°Ґїщ”Џѕя–‘÷І≥÷ѕтЅњїъµƒ‘§≤вƒ£њйЇЌЋЃќс∆љћ®ќџЋЃЉм≤в„”ѕµЌ≥;Ћщ ц эЊЁ д»лƒ£њй∞ьј®јъ Ј эЊЁіжіҐ∆ч°Ґ µ ± эЊЁїЇіж∆ч“‘Љ∞∆ЏЌы эЊЁіжіҐ∆ч;∆д÷–£Ї
°°°°јъ Ј эЊЁіжіҐ∆ч”√”ЏіжіҐќџЋЃі¶јн≥І„ољьЉЄћм µ ±Љм≤вµљµƒЋЃќс эЊЁ;
°°°°∆ЏЌы эЊЁіжіҐ∆ч”√”ЏіжіҐќџЋЃі¶јнµƒ––“µ±к„Љµƒ эЊЁ;
°°°° µ ± эЊЁїЇіж∆ч”√”ЏїЇіж µ ±Ља≤вµљµƒЋЃќс эЊЁ;
°°°°їщ”Џѕя–‘÷І≥÷ѕтЅњїъµƒ‘§≤вƒ£њй”√”ЏЄщЊЁјъ Ј эЊЁіжіҐ∆чЇЌ∆ЏЌы эЊЁіжіҐ∆чµƒ эЊЁґ‘ µ ± эЊЁїЇіж∆ч÷–µƒ эЊЁљш––‘§≤в;
°°°°ЋЃќс∆љћ®ќџЋЃЉм≤в„”ѕµЌ≥”√”Џїс»°ЋЃќс–≈ѕҐ°£
°°°°4.ЄщЊЁ»®јы“™«у1Ћщ цµƒ“ї÷÷їщ”Џїъ∆ч—Іѕ∞µƒќџЋЃі¶јнµƒЋЃ÷ ‘§≤вѕµЌ≥£ђ∆дћЎ’ч‘Џ”Џ£ђЋщ цЋЃќс∆љћ®ќџЋЃЉа≤в„”ѕµЌ≥∞ьј® эЊЁ≤…Љѓµ•‘™ЇЌ эЊЁіжіҐіт”°µ•‘™£ђЋщ ц эЊЁ≤…Љѓµ•‘™∞ьј®CODcr≥цЋЃЉм≤в„∞÷√°ҐPH÷µЉм≤в„∞÷√°Ґ»№љв—хDOЉм≤в„∞÷√°Ґ∞±µ™NH3-NЉм≤в„∞÷√; эЊЁ≤…Љѓµ•‘™љЂЄчЄцЉм≤в„∞÷√Љм≤вµƒќџЋЃµƒ≤вЅњ≤ќ эЌ®єэ эЊЁіжіҐіт”°µ•‘™іжіҐіт”°°£
°°°°5.ЄщЊЁ»®јы“™«у4Ћщ цµƒ“ї÷÷їщ”Џїъ∆ч—Іѕ∞µƒќџЋЃі¶јнµƒЋЃ÷ ‘§≤вѕµЌ≥£ђ∆дћЎ’ч‘Џ”Џ£ђќџЋЃі¶јн≥Іµƒ√њ÷÷ќџЋЃі¶јн…и±Єµƒ≥цЋЃњЏ÷Ѕ…ў…и÷√”–“їЄц эЊЁ≤…Љѓµ•‘™°£
°°°°6.ЄщЊЁ»®јы“™«у1Ћщ цµƒ“ї÷÷їщ”Џїъ∆ч—Іѕ∞µƒќџЋЃі¶јнµƒЋЃ÷ ‘§≤вѕµЌ≥£ђ∆дћЎ’ч‘Џ”Џ£ђїщ”Џѕя–‘÷І≥÷ѕтЅњїъµƒ‘§≤вƒ£њй∞ьј®ѕя–‘÷І≥÷ѕтЅњїъ£ђљЂјъ Ј эЊЁіжіҐ∆ч÷–µƒ эЊЁЇЌ∆ЏЌы эЊЁіжіҐ∆чµƒ эЊЁ д»лѕя–‘÷І≥÷ѕтЅњїъљш––—µЅЈїсµ√ћЎ’ч»®÷µ£ђѕя–‘÷І≥÷ѕтЅњїъ—µЅЈїсµ√„о”≈ћЎ’ч»®÷µµƒєэ≥ћ÷–£ђµч”√ѕя–‘÷І≥÷ѕтЅњїъ‘Џ—й÷§Љѓ…ѕµƒ–‘ƒ№F1Ј÷ э„чќ™…Є—°ћЎ’ч»®÷µµƒ÷Є±к;љЂ µ ± эЊЁїЇіж∆ч÷–µƒ эЊЁ„чќ™ѕя–‘÷І≥÷ѕтЅњїъµƒ д»л£ђѕя–‘÷І≥÷ѕтЅњїъ д≥цґ‘ќџЋЃі¶јнµƒ‘§≤вљбєы°£
°°°°Ћµ√ч й
°°°°“ї÷÷їщ”Џїъ∆ч—Іѕ∞µƒќџЋЃі¶јнµƒЋЃ÷ ‘§≤вЈљЈ®Љ∞ѕµЌ≥
°°°°ЉЉ хЅм”т
°°°°±ЊЈҐ√ч…жЉ∞їъ∆ч—Іѕ∞Ѕм”т£ђћЎ±р…жЉ∞“ї÷÷їщ”Џїъ∆ч—Іѕ∞µƒќџЋЃі¶јнµƒЋЃ÷ ‘§≤вЈљЈ®Љ∞ѕµЌ≥°£
°°°°±≥Њ∞ЉЉ х
°°°°ЋЃїЈЊ≥÷ќјн“ї÷± «√с…ъєЎ–ƒµƒ“їіуќ ћв£ђ∆д÷–ќџЋЃі¶јнЄь «µЏ“ї“™ќс°£ѕ÷љ„ґќ£ђЋж„≈ќ“єъ…зїбЋЃ∆љ÷р≤љћбЄя°Ґє§“µїѓЈҐ’є≥ћґ»µƒЉ”…о£ђ…зїб”√ЋЃ–и«уЅњіу£ђє§“µќџЋЃ≈≈Ј≈Ѕњ‘цЉ”£ђ єќ“єъЋЃ„ ‘іїЈЊ≥‘вµљ“їґ®≥ћґ»µƒ∆∆їµ£ђЋЃ„ ‘іґћ»±°ҐЋЃ…ъћђЋрЇ¶°ҐЋЃїЈЊ≥ќџ»Њµ»ќ ћв‘љјі‘љЌї≥ц£ђЋЃ∞≤»Ђ±£’ѕ√жЅў—ѕЊюµƒћф’љ°£‘Џ’юЄЃЋЃќс÷ќјнєжїЃ÷–£ђЇЏ≥фЋЃће’ы÷ќЄь «ƒњ«∞≥«’тЋЃќсє§„чµƒ÷Ў÷–÷Ѓ÷Ў°£“тіЋ£ђќ™ЅЋіўљшќ“єъ…ъћђќƒ√чµƒљ®…и£ђЉх…ўЋЃ„ ‘іјЋЈ—£ђ–и“™„цЇ√ќџЋЃі¶јнє§„ч£ђЉ”«њЋЃ„ ‘іµƒ—≠їЈ”¶”√£ђіпµљќ“єъњ…≥÷–шЈҐ’єµƒєжїЃ°£
°°°°љьƒкјі£ђЋж„≈ЋЃќс÷ќјнє§„чµƒЌ∆љш£ђќџЋЃі¶јнµƒ«йњцµ√µљљѕіуЄƒ…∆°£µЂќџЋЃі¶јнєэ≥ћ «“їЄц±дЅњЈ±ґа°ҐЊя”– ±÷ЌћЎµгµƒґѓћђЈ«ѕя–‘Јі”¶єэ≥ћ°£»зєыќ“√«ƒ№і”“‘ЌщµƒќџЋЃЋЃ÷ эЉм≤в±к„Љ эЊЁ‘§≤в≥ц“‘Їу µ ±љ„ґќµƒЋЃ÷ эЊЁ£ђґ‘ЉіљЂЌїЈҐµƒЋЃ÷ ќ ћвљш––‘§Њѓ°ҐЉ∞ ±і¶јн°£ґ‘”ЏЋЃќсє§≥Іµƒ≥§∆Џ∞≤ќ»‘Ћ––Њя”–÷Ў“™µƒ“в“е
°°°°‘Џѕ÷”–µƒќџЋЃі¶јнЅм”т÷–£ђ’лґ‘”ЏќџЋЃ≥ІЋЃ÷ ‘§≤вѕ÷љ„ґќіу≤њЈ÷ «»Ћє§µƒЈљ љ»•…иЉ∆їтћб»°ЋЃ÷ эЊЁµƒћЎ’чјі µѕ÷ эЊЁµƒі¶јн,’в÷÷ЈљЈ®µƒ»±µг‘Џ”Џ–и“™ЇƒЈ—іуЅњµƒјЌґѓЅ¶«“µ√≥цµƒћЎ’чЌщЌщЊ÷ѕё”ЏћЎґ®µƒ»ќќс£ђ≤Ґ«“„о÷ч“™µƒќ ћв‘Џ”Џ”…”ЏќџЋЃЋЃ÷ « µ ±±дїѓµƒµ±ќџЋЃЋЃ÷ ≥цѕ÷ќ ћвЇу≤їƒ№±£÷§ µ ±µƒљвЊц°£“тіЋѕ÷”–ЉЉ хЌщЌщ÷±љ”≤…”√іЂЌ≥µƒ–≈ѕҐЉмЋч÷–µƒ“ї–©ЈљЈ®јіћб»°ЋЃ÷ эЊЁ÷–µƒћЎ’чґш’в–©іЂЌ≥ЈљЈ®≤Ґ≤їƒ№Ї№Ї√≤ґ„љµљќ“√«Ћщ–и“™µƒ–≈ѕҐ£ђ≤Ґ«“≤їƒ№Љ∞ ±µƒґ‘≥цѕ÷µƒќ ћвљш––≤єЊ»°£
°°°°ЈҐ√чƒЏ»Ё
°°°°ќ™ЅЋЄьЉ””––ІµЎґ‘ќџЋЃі¶јнљш––‘§≤в£ђ±ЊЈҐ√чћб≥ц“ї÷÷їщ”Џїъ∆ч—Іѕ∞µƒќџЋЃі¶јнµƒЋЃ÷ ‘§≤вЈљЈ®Љ∞ѕµЌ≥£ђЋщ цЈљЈ®Њяће∞ьј®“‘ѕ¬≤љ÷и£Ї
°°°°S1°Ґ»Јґ®ќџЋЃµƒ≤вЅњ≤ќ эЇЌќџЋЃі¶јнµƒ––“µ±к„Љ£ђ≤Ґ≥х ЉїѓќџЋЃµƒ≤вЅњ≤ќ э£ђ≤ҐљЂ≤вЅњ≤ќ эµƒћЎ’ч»®÷ЎѕтЅњ≥х Љїѓќ™1ќ™v0(i)=1;
°°°°S2°ҐЌ®єэѕя–‘÷І≥÷ѕтЅњїъїс»°ќџЋЃ≤вЅњ≤ќ эµƒ ”¶ґ»£ђљЂ ”¶ґ»„оіуµƒЄцће„чќ™„о”≈µƒЄцће£ђЅоi=1;
°°°°S3°Ґ‘ЏµЏiіќµьіъ÷–£ђљЂ„о”≈µƒЄцћеЄі÷∆n-1Єц£ђ≤Ґ‘Џ√њЄцЄі÷∆µƒЄцће…ѕµƒћЎ’ч»®÷Ў…ѕЋжїъЉ”…ѕ“їЄц[0,max_variation]µƒ÷µ;
°°°°S4°ҐЌ®єэѕя–‘÷І≥÷ѕтЅњїъїс»°µ±«∞Єцћеµƒ ”¶ґ»£ђ—°‘с ”¶ґ»„оіуµƒЄцће„чќ™„о”≈µƒЄцће;
°°°°S5°Ґ≈–ґѕ «Јсіпµљ„оіуµьіъіќ э£ђ»ф√їіпµљ‘тЅоi=i+1£ђЈµїЎ≤љ÷иS3;Јс‘т д≥ц„о”≈µƒћЎ’ч»®÷ЎѕтЅњ;
°°°°S6°ҐљЂµ√µљ„о”≈ћЎ’чѕтЅњ д»лѕя–‘÷І≥÷ѕтЅњїъ£ђЌк≥…—µЅЈ;љЂ µ ±ќџЋЃ≤вЅњ≤ќ э д»лЌк≥…—µЅЈµƒѕя–‘÷І≥÷ѕтЅњїъЉіњ…µ√µљ‘§≤вљбєы;
°°°°∆д÷–£ђnќ™‘§ґ®µƒ÷÷»Ї эЅњ;max_variationќ™‘§…иµƒµ•іъ„оіу±д“мґ»;vj(i)ќ™µЏjЄцќџЋЃµƒ≤вЅњ≤ќ эµƒћЎ’чѕтЅњ£ђ1°№i°№m£ђmќ™Є√≤вЅњ≤ќ эµƒћЎ’чѕтЅњµƒќђ э°£
°°°°љш“ї≤љµƒ£ђЋщ ц ”¶ґ»ќ™ЄцћеµƒF1Ј÷ э£ђF1Ј÷ эќ™÷І≥÷ѕтЅњїъ‘Џ—й÷§Љѓ…ѕµƒ–‘ƒ№≤ќ э°£
°°°°Ћщ цќџЋЃµƒ≤вЅњ≤ќ э÷Ѕ…ў∞ьј®CODcr≥цЋЃ°ҐPH÷µ°Ґ»№љв—хDO°Ґ∞±µ™NH3-N°£
°°°°±ЊЈҐ√чїєћб≥ц“ї÷÷їщ”Џїъ∆ч—Іѕ∞µƒќџЋЃі¶јнµƒЋЃ÷ ‘§≤вѕµЌ≥£ђ∞ьј® эЊЁ д»лƒ£њй°Ґїщ”Џѕя–‘÷І≥÷ѕтЅњїъµƒ‘§≤вƒ£њйЇЌЋЃќс∆љћ®ќџЋЃЉм≤в„”ѕµЌ≥;Ћщ ц эЊЁ д»лƒ£њй∞ьј®јъ Ј эЊЁіжіҐ∆ч°Ґ µ ± эЊЁїЇіж∆ч“‘Љ∞∆ЏЌы эЊЁіжіҐ∆ч;∆д÷–£Ї
°°°°јъ Ј эЊЁіжіҐ∆ч”√”ЏіжіҐќџЋЃі¶јн≥І„ољьЉЄћм µ ±Љм≤вµљµƒЋЃќс эЊЁ;
°°°°∆ЏЌы эЊЁіжіҐ∆ч”√”ЏіжіҐќџЋЃі¶јнµƒ––“µ±к„Љµƒ эЊЁ;
°°°° µ ± эЊЁїЇіж∆ч”√”ЏїЇіж µ ±Ља≤вµљµƒЋЃќс эЊЁ;
°°°°їщ”Џѕя–‘÷І≥÷ѕтЅњїъµƒ‘§≤вƒ£њй”√”ЏЄщЊЁјъ Ј эЊЁіжіҐ∆чЇЌ∆ЏЌы эЊЁіжіҐ∆чµƒ эЊЁґ‘ µ ± эЊЁїЇіж∆ч÷–µƒ эЊЁљш––‘§≤в;
°°°°ЋЃќс∆љћ®ќџЋЃЉм≤в„”ѕµЌ≥”√”Џїс»°ЋЃќс–≈ѕҐ°£
°°°°љш“ї≤љµƒ£ђЋщ цЋЃќс∆љћ®ќџЋЃЉа≤в„”ѕµЌ≥∞ьј® эЊЁ≤…Љѓµ•‘™ЇЌ эЊЁіжіҐіт”°µ•‘™£ђЋщ ц эЊЁ≤…Љѓµ•‘™∞ьј®CODcr≥цЋЃЉм≤в„∞÷√°ҐPH÷µЉм≤в„∞÷√°Ґ»№љв—хDOЉм≤в„∞÷√°Ґ∞±µ™NH3-NЉм≤в„∞÷√; эЊЁ≤…Љѓµ•‘™љЂЄчЄцЉм≤в„∞÷√Љм≤вµƒќџЋЃµƒ≤вЅњ≤ќ эЌ®єэ эЊЁіжіҐіт”°µ•‘™іжіҐіт”°°£
°°°°љш“ї≤љµƒ£ђќџЋЃі¶јн≥Іµƒ√њ÷÷ќџЋЃі¶јн…и±Єµƒ≥цЋЃњЏ÷Ѕ…ў…и÷√”–“їЄц эЊЁ≤…Љѓµ•‘™°£
°°°°љш“ї≤љµƒ£ђїщ”Џѕя–‘÷І≥÷ѕтЅњїъµƒ‘§≤вƒ£њй∞ьј®ѕя–‘÷І≥÷ѕтЅњїъ£ђљЂјъ Ј эЊЁіжіҐ∆ч÷–µƒ эЊЁЇЌ∆ЏЌы эЊЁіжіҐ∆чµƒ эЊЁ д»лѕя–‘÷І≥÷ѕтЅњїъљш––—µЅЈїсµ√ћЎ’ч»®÷µ£ђѕя–‘÷І≥÷ѕтЅњїъ—µЅЈїсµ√„о”≈ћЎ’ч»®÷µµƒєэ≥ћ÷–£ђµч”√ѕя–‘÷І≥÷ѕтЅњїъ‘Џ—й÷§Љѓ…ѕµƒ–‘ƒ№F1Ј÷ э„чќ™…Є—°ћЎ’ч»®÷µµƒ÷Є±к;љЂ µ ± эЊЁїЇіж∆ч÷–µƒ эЊЁ„чќ™ѕя–‘÷І≥÷ѕтЅњїъµƒ д»л£ђѕя–‘÷І≥÷ѕтЅњїъ д≥цґ‘ќџЋЃі¶јнµƒ‘§≤вљбєы°£
°°°°±ЊЈҐ√чћб≥цµƒ“ї÷÷їщ”Џїъ∆ч—Іѕ∞µƒќџЋЃі¶јнЋЃ÷ ‘§≤вЈљЈ® «їщ”Џ“≈іЂЋгЈ®”л÷І≥÷ѕтЅњїъµƒЋЃ÷ „ц≥ц‘§≤вƒ£–Ќґ‘”Џ’ыЄц‘≠ Љ эЊЁљш––≥х Љїѓ£ђјы”√“≈іЂЋгЈ®…Є—°≥ц„оЉ—ћЎ’ч»®÷Ўјіґ‘‘≠ Љ эЊЁљш––Љ”»®Ј≈Ћх£ђ—µЅЈƒ£–Ќґ‘ќџЋЃі¶јнЋЃ÷ Ќк≥…‘§≤в;ґ‘”Џ’ыЄц‘≠ Љ эЊЁ(‘≠ Љ эЊЁ≤ќ э)љш––≥х Љїѓ£ђ≤ҐљЂ∆д»®÷ЎґЉ…и÷√ѕаЌђљш––±к„Љїѓ;∆діќјы”√“≈іЂЋгЈ®…Є—°≥ц„оЉ—ћЎ’ч»®÷Ўvkјіґ‘‘≠ Љ эЊЁљш––Љ”»®Ј≈Ћх;„оЇујы”√Љ”»®Їуµƒ эЊЁґ‘÷І≥÷ѕтЅњїъƒ£–Ќљш––—µЅЈµ√µљ„о÷’µƒќџЋЃЋЃ÷ ‘§≤вƒ£–Ќ£ђіпµљ µ ±‘§≤вќџЋЃ÷ Ѕњ£ђ»Ћќ™љш––Є®÷ъµчњЎµƒƒњµƒ°££®ЈҐ√ч»Ћ¬ніі;‘ђ“∞;”»Ї£…ъ£©